안녕하세요. 주식 관련 데이터를 분석하는 투자자 인천고래입니다.
준비에 준비를 한 결과 어제부터 딥러닝을 하기 시작했습니다.
딥러닝을 하게 된 계기가 좀 없어 보이지만 일전에 확률이 높은 매매법으로 매수, 매도 시그널을 받아보면서 시그널에 대한 피드백을 주실 수 있는 분을 모집(?)하는 글을 올렸었는데
엄청나게도 한 분도 지원을 안해주셔서 '아~ 내가 잘못 생각했구나'라는 생각이 들어서 (해당 글은 비공개처리)
혼자서라도 검증하면서 확률을 높일 수 있는 방법을 찾다가 딥러닝을 대안으로 찾게 되었습니다.
그래서 오늘은 딥러닝에 대한 글을 주제로 써 볼까합니다.

딥러닝 구축 방법에 관하여
일단 시계열타입(주식과 같이 날짜가 있는)의 딥러닝이라는 게 하나의 데이터(종가)를 가지고 학습의 횟수(에포크, epoch)에 맞게 학습을 하게 되며 효율적인 결과를 자동적으로 찾는 것이라고 보시면 됩니다.
1. 딥러닝의 구축 단계
우선은 간단하게 아래와 같은 단계로 딥러닝 구축 계획을 세운 뒤 실행을 했습니다.
- 데이터 수집:
주식 데이터는 여러 웹사이트나 API를 통해 수집할 수 있습니다만
저는 FinanceDataReader를 사용해서 데이터를 수집했고 이동평균선 데이터와 이동평균선 데이터를 가공한 저 만의 계산 방식으로 만든 지표하나를 추가해서 데이터를 만들었습니다.
자신만의 지표가 없는 경우라 하더라도 종가, 시가, 고가, 저가, 거래량 등의 기본 정보로도 딥 러닝은 가능하며 파이썬에서 지원하는 다양한 기술적 지표(TA: Technical Analysis)나 재무제표 데이터 등도 고려해 볼 수 있습니다. - 데이터 전처리:
결측값 처리, 정규화(normalization), 표준화(standardization) 등의 전처리 과정이 꼭 필요합니다. 시계열 데이터의 특성을 고려하여 데이터를 차분하거나, 이동평균을 적용할 수도 있는데 문제는 서두에 언급한 결측, 정규화, 표준화 작업을 거쳐야 한다는 것이죠.
예를 들어 주식 기본 데이터를 통해 이동평균선을 120일선에 대한 것을 만들 경우에는 아래와 같이 코드를 작성할 수 있습니다.
그런데 데이터를 만들고 끝나는 것이 아니라 결측값에 대해 처리를 한다고 하면 120일선 데이터를 만들기 위해서는 120일에 대한 데이터가 있어야 1개의 120일선 데이터가 만들어지는데 그 앞의 비어있는 행들이 바로 '결측값'이라고 부르는 딥러닝에서는 무조건 없애야 하는 비어있는 데이터가 됩니다.def calculate_moving_average(df, periods): for p in periods: df[f"MA{p}"] = df['Close'].rolling(p).mean() return df
이와 같은 단계 단계를 거쳐서 데이터 전처리를 완벽하게 해 두어야 그다음 단계로 진입을 할 수 있습니다. - 모델 구축:
LSTM(Long Short-Term Memory), GRU(Gated Recurrent Units), CNN(Convolutional Neural Networks)와 같은 딥러닝 모델들은 시계열 데이터에 대한 예측에 효과적으로 알려져 있고 처음 시작을 하시는 분들은 복잡한 모델을 사용하기 전에 간단한 모델로 시작하여 기본 성능을 확인하는 것이 좋습니다.
저는 LSTM(Long Short-Term Memory) 방식을 사용해서 모델을 구축했습니다.
아래는 구축한 모델링 코드입니다.
''' # 2. 모델 구축 (여기서는 간단한 LSTM 모델 예시) ''' model = Sequential() model.add(LSTM(50, input_shape=(train_X.shape[1], train_X.shape[2]), return_sequences=True)) model.add(LSTM(50)) model.add(Dense(3, activation='softmax')) # 매수, 매도, 보류 3개의 클래스 model.compile(loss='categorical_crossentropy', optimizer='adam', metrics=['accuracy']) if stock_code in last_epochs: last_epoch = last_epochs[stock_code] if last_epoch > 0: # 체크포인트가 있다면 last_checkpoint_path = f"{h5_folder_path}\\{stock_code}_checkpoint_{last_epoch:02d}.h5" model.load_weights(last_checkpoint_path) print(f"{stock_code}의 마지막 체크포인트를 로드했습니다: 에포크 {last_epoch}") # 체크포인트 경로 설정: 각 종목별로 체크포인트 파일 이름에 종목 코드를 포함 # checkpoint_path = f"{base_path}\\{stock_code}_checkpoint.h5" checkpoint_path = f"{h5_folder_path}\\{stock_code}_checkpoint_{{epoch:02d}}.h5" checkpoint = ModelCheckpoint(checkpoint_path, monitor='val_loss', verbose=1, save_best_only=False, mode='auto', save_freq='epoch') - 모델 학습:
주식 시장의 데이터는 노이즈가 많을 수 있으므로, 과적합(overfitting)을 피하기 위한 규제(regularization) 기법을 적용하는 것이 중요합니다고 합니다. 저 역시 알아가고 있는 단계이며 근본적으로는 학습률(learning rate), 배치 크기(batch size), 에포크 수(epochs) 등의 하이퍼파라미터를 조절하면서 최적의 설정을 찾아나가야 합니다.
저는 학습을 할 때 에포크수를 100 정도로 설정을 해두고 배치사이즈는 64 정도로 해둡니다.
# 학습 시작 total_epochs = 100 history = model.fit(train_X, train_y_encoded, epochs=total_epochs, batch_size=64, validation_data=(test_X, test_y_encoded), verbose=1) # History 객체를 DataFrame으로 변환 후 CSV 파일로 저장 history_df = pd.DataFrame(history.history) history_df.to_csv(f"{h5_folder_path}\\{stock_code}_history.csv", index=False) # 모델저장 # model.save(f"{h5_folder_path}\\{stock_code}_model.h5") model.save(f"{h5_folder_path}\\{stock_code}_model.keras") # 학습한 loss와 val_loss 그래프로 표시 plt.plot(history.history['loss'], label='Train Loss') plt.plot(history.history['val_loss'], label='Validation Loss') plt.title(f'Loss for {stock_code}') plt.xlabel('Epochs') plt.ylabel('Loss') plt.legend() plt.savefig(f"{base_path}\\loss_graph\\{stock_code}_loss_graph.png") # 저장된 가중치 불러오기 (필요한 경우 사용) # model.load_weights(checkpoint_filepath) - 평가 및 테스트:
학습 데이터와는 별도로 검증 데이터와 테스트 데이터를 활용하여 모델의 성능을 평가하는 단계입니다. 딥러닝으로 나온 결과를 그대로 믿고 실제로 매매를 하시면 안 되겠죠? 그전에는 백테스팅(backtesting)을 통해 모델의 성능을 평가해 보는 것이 좋습니다.
''' 4. 평가 ''' # 모델을 사용하여 예측을 수행합니다. predictions = model.predict(test_X) # 예측된 라벨과 실제 라벨 비교 predicted_labels = np.argmax(predictions, axis=1) # 가장 확률이 높은 라벨 선택 actual_labels = test_y print(f'actual_labels {actual_labels}') accuracy = np.mean(predicted_labels == actual_labels) print(f"Accuracy for {stock_code}: {accuracy:.2f}") # 분류 보고서 출력 report = classification_report(actual_labels, predicted_labels, target_names=['매수', '매도', '보류']) # 혼동 행렬 출력 cm = confusion_matrix(actual_labels, predicted_labels) # 분류 보고서와 혼동 행렬을 파일에 저장 output_path_lstm = f"{h5_folder_path}\\{stock_code}_lstm_report.txt" with open(output_path_lstm, 'w', encoding='utf-8') as f: # 정확도 저장 f.write(f"Accuracy for {stock_code}: {accuracy:.2f}\n\n") # 분류 보고서 저장 report = classification_report(actual_labels, predicted_labels, target_names=['매수', '매도', '보류']) f.write("Classification Report:\n") f.write(report) f.write("\n\n") # 혼동 행렬 저장 cm = confusion_matrix(actual_labels, predicted_labels) f.write("Confusion Matrix:\n") for row in cm: f.write(" ".join(str(x) for x in row)) f.write("\n") print(f"결과가 {output_path_lstm}에 저장되었습니다.") - 매매 전략 개발:
예측한 결과를 바탕으로 매매 전략을 세워야 하는데 지금은 딥 러닝이 계속 학습을 하고 있는 단계이기 때문에 차후에 이와 관련해서는 간략하게나마 코멘트를 하도록 하겠습니다.
어때 보이나요?
어제 시작한 것 치고는 많은 코드와 결과를 얻어가고 있는 중입니다.
2. 딥러닝을 활용한 결과물
우선 기본적인 데이터(종가)로만 딥러닝을 돌린 결과물을 보여드리도록 하겠습니다.
아래의 차트를 보면 로그 차트처럼 보이는데
에포크 1부터 100까지 돌렸을 때 실제값과 예상값의 결과 차이를 보여주는 것으로 Loss율이 낮으면 낮을수록 정확도가 높아지는 것으로 생각하시면 됩니다.
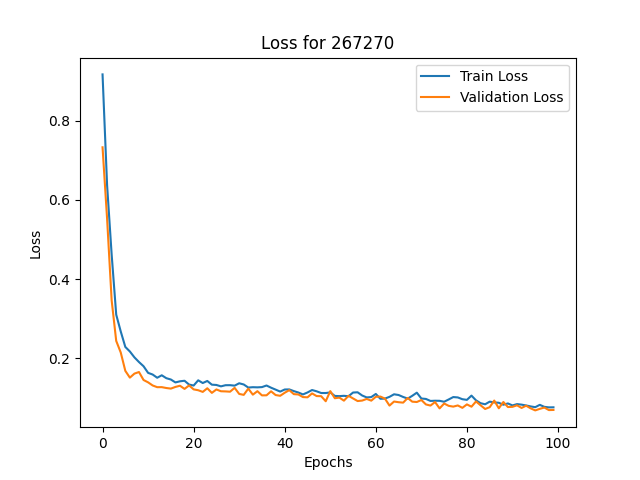
실제 차트의 주가(파란색 실선)와 딥러닝 학습을 처음 할 때의 예상 주가(빨간색 점선)의 차이를 보면 간극이 크다는 것을 느낄 수 있습니다. 위의 이미지에서 보면 Epochs가 0에 해당하는 Loss율이 1에 근접한 경우가 아래와 같이 나온 것이라 생각하시면 됩니다.

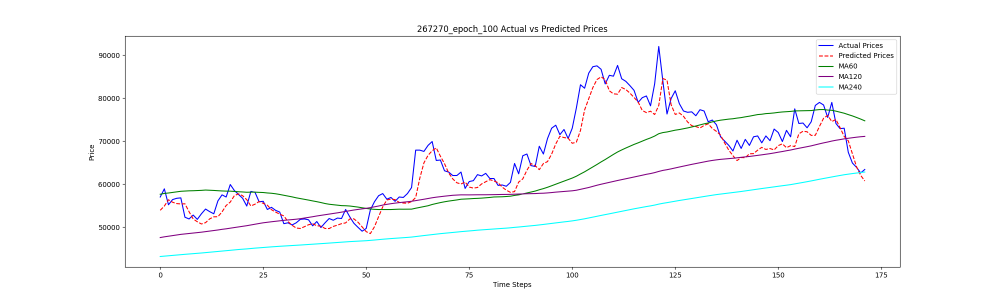
그럼 딥러닝으로 100번의 에포크를 돌렸을 때의 결과물을 확인해 보도록 하겠습니다.
실제 주가와 예상 주가의 차이가 큰 차이가 없이 거의 동일한 형태를 잡아가는 것으로 보입니다.
사실 30개 정도의 차트만 돌려서 학습효과가 크진 않지만 간략하게 돌린(12시간 동안 코드 만들고 12시간 학습 돌림) 결과물치고는 나쁘지 않습니다.
아래의 결과물에서 나쁘다고 할만한 점은 예상 주가가 실제 주가보다 앞에서 이루어졌으면 대박이겠다는 생각을 해 봅니다. 이상적인 결과물을 얻기 위해 무엇을 해야 할지 고민을 많이 해 보아야 할 것 같습니다.
3. 마무리
코딩을 하지 않는 일반 투자자 분들께서 딥러닝을 하기는 어려우실 것으로 생각이 듭니다만
자신만의 매매기법이 확고하신 즉, 수익이 꾸준히 발생하는 분들은 딥러닝을 배우든 코딩을 배워서라도 자동매매로 전향을 하셔야 합니다. 언제까지 모니터 앞에서 계속 앉아 있을 수는 없잖아요~ 인생을 즐겨야죠~
저 역시 자동매매로 수익을 얻을 수 있도록 부단히 노력하고 있습니다. ^^ 함께 부자 되어보아요~
딥러닝 관련해서 글을 쓴 만큼 개별적으로 기초적이면서도 중요하다고 생각한 부분을 언급하며 글을 마무리 짓도록 하겠습니다.
모델학습을 재개하는 방법과 관련하여
- 체크포인트 저장 및 로드:
TensorFlow나 PyTorch에서는 모델의 상태를 저장하고 불러오는 기능을 제공하기 때문에
학습 중인 모델의 가중치나 파라미터를 주기적으로 체크포인트로 저장하도록 하고. 데이터를 업데이트한 후, 저장된 체크포인트를 로드하여 학습을 재개하도록 해야 합니다. - 새로운 데이터로만 학습 (Incremental Learning):
기존에 학습된 모델을 기반으로, 새롭게 업데이트된 데이터만을 사용하여 모델을 추가로 학습시키는 방식입니다. 이 방식은 새로운 데이터가 기존 데이터와 크게 다르지 않을 때 유용하며, 학습 시간을 크게 단축시킬 수 있습니다.
사실 데이터를 업데이트하면서 학습을 재개하는 경우 몇 가지 주의사항이 있습니다
과적합(Overfitting): 모델이 새로운 데이터에 지나치게 최적화될 수 있으므로, 검증 데이터를 활용하여 모델의 성능을 지속적으로 모니터링.
학습률(Learning Rate): 학습을 재개할 때, 초기 학습률보다 낮은 학습률을 사용하는 것을 고려. 이는 모델이 빠르게 수렴하는 것을 방지하고, 미세 조정(fine-tuning)을 돕습니다.
요약하면, 데이터를 업데이트한 후 학습을 재개하는 것은 가능하며, 효과적인 방법들이 있습니다. 처음부터 모델을 다시 학습시키는 것보다 훨씬 빠른 시간 안에 학습을 완료할 수 있습니다.
딥러닝은 모든 단계가 다 중요하지만 학습과 모델링이 제일 중요하다고 생각합니다.
오늘도 제 글을 읽어주셔서 감사의 말씀을 드립니다. 감사합니다.
'이전 게시글 > Quant' 카테고리의 다른 글
| 주식 목표 주가 알림(알람) 프로그램 - 소스 코드 공유 (3) | 2024.06.07 |
|---|---|
| 구글 시트(API)와 플라스크(Flask) 연동하기 : 목차 (1) | 2023.12.22 |
| 9월 27일 상한가 기준봉 눌림목 종목 리스트 (종목별 테마) (8) | 2023.09.27 |
| 기준봉 진입 종목 리스트를 공유할 예정입니다.(8월 22일 데이터 포함) (2) | 2023.08.22 |
| 박스권 돌파 종목 - KOSPI (2023년 4월 18일 예상종목) (0) | 2023.04.17 |



